The FIPS 180-4 Standard details the secure hash algorithm, SHA-256, which operates as an iterative, one-way hash function. SHA-256 processes input messages to generate condensed representations called message digests. These digests are pivotal in ensuring the integrity of messages: any changes made to the original message will almost certainly produce a distinct message digest. This property proves crucial for activities such as generating and validating digital signatures, message authentication codes, and random numbers or bits.
SHA-256 can be divided into two stages: preprocessing and hash computation.
Preprocessing involves padding the message, dividing the padded message into
blocks of m bits, and initializing values for the hash computation. The hash
computation utilizes the padded message to generate a message schedule, which,
along with specific functions, constants, and word operations, iteratively
constructs a series of hash values. The final hash value determined by the
hash computation ultimately decides the message digest. What follows is a
step-by-step guide on how to implement SHA-256 using the Go programming language.
SHA-256 plays a pivotal role in Bitcoin’s foundational design as it serves as the basis for its proof-of-work consensus mechanism. This cryptographic hash function is used to create hash values that represent transaction data and, importantly, to mine new blocks on the blockchain. The computational effort required for mining, based on solving SHA-256 puzzles, ensures the security of the network and validates transactions. The highly secure and irreversible nature of SHA-256 hashing provides Bitcoin with the immutability necessary for a decentralized, trustless, and tamper-resistant digital currency system.
Preprocessing consists of three steps: padding the message, M, parsing the
message into message blocks, and setting the initial hash value, H.
In the context of the SHA-256 hashing algorithm, the padding process ensures that the input message conforms to a multiple of 512 bits, as dictated by the algorithm’s requirements. This is accomplished through a series of steps:
func padding(m []byte) []byte {
// length of the message m in bits
l := len(m) * 8
// number of zero paddding bits needed
plen := 512 - (l+8+64)%512
// byte slice of zeros needed
p := make([]byte, plen/8)
// add the '1' bit to the end of the message
m = append(m, 0x80)
// append the padding bytes
m = append(m, p...)
// length of the original message in binary
mlen := make([]byte, 8)
binary.BigEndian.PutUint64(mlen, uint64(l))
// append the length of the original message in bits
m = append(m, mlen...)
return m
}
Initially, the length of the input message m is calculated in bits, and the number
of zero padding bits needed to reach the next multiple of 512 bits is determined as
plen. Subsequently, a byte slice of zeros p is created, equal to plen divided
by 8, to fulfill the padding requirement.
The padding process continues by appending a single ‘1’ bit to the end of the
original message m. This step ensures that there’s a clear separation between
the original message and the padding itself. Subsequently, the previously generated
zero padding bytes p are appended to the message.
The final aspect of the padding process involves adding the length of the original
message in binary to the message. This length, denoted as mlen, is represented
using 8 bytes in big-endian format. Appending the binary length of the original
message is essential for maintaining the integrity and integrity-checking
capabilities of the hash.
For example, the (8-bit ASCII) message “abc” becomes the following 512-bit padded message:

After applying the padding to the input message, the resulting padded message
is divided into N 512-bit message blocks to facilitate further processing.
This crucial step ensures that the algorithm can efficiently process the message
in chunks, aiding in the calculation of the hash value. The implementation is
pretty straightforward:
func parsing(m []byte) [][]byte {
var mb [][]byte
n := len(m) / chunk
for i := 0; i < n; i++ {
mb = append(mb, m[i*chunk:(i+1)*chunk])
}
return mb
}
Before hash computation begins for each of the secure hash algorithms, the initial hash value must be set. For SHA-256, the initial hash value, shall consist of the following eight 32-bit words, in hex:

These words were obtained by taking the first thirty-two bits of the fractional parts of the square roots of the first eight prime numbers.
Once preprocessing is completed, what follows is the hash computation. The algorithm uses a message schedule of sixty-four 32-bit words, eight working variables of 32 bits each, and a hash value of eight 32-bit words. The final result of SHA-256 is a 256-bit message digest.
Before going any further, lets define functions and constants that are used in hash computation.
SHA-256 uses six logical functions, where each function operates on 32-bit words,
which are represented as x, y, and z. The result of each function is a
new 32-bit word.

Notice, that there are operations also defined as part of the logical functions. The operations are applied to the 32-bit words and can be found in the standard.
SHA-256 uses a sequence of sixty-four constant 32-bit words. These words represent the first thirty-two bits of the fractional parts of the cube roots of the first sixty-four prime numbers. In hex, these constant words are (from left to right):

Now, preparing the message schedule (also known as the “W array”) involves breaking
down the input message into 512-bit blocks (as we have already done) and further
dividing each block into 16 32-bit words (W[0] through W[15]), and then extending
these words using a recurrence relation defined as:
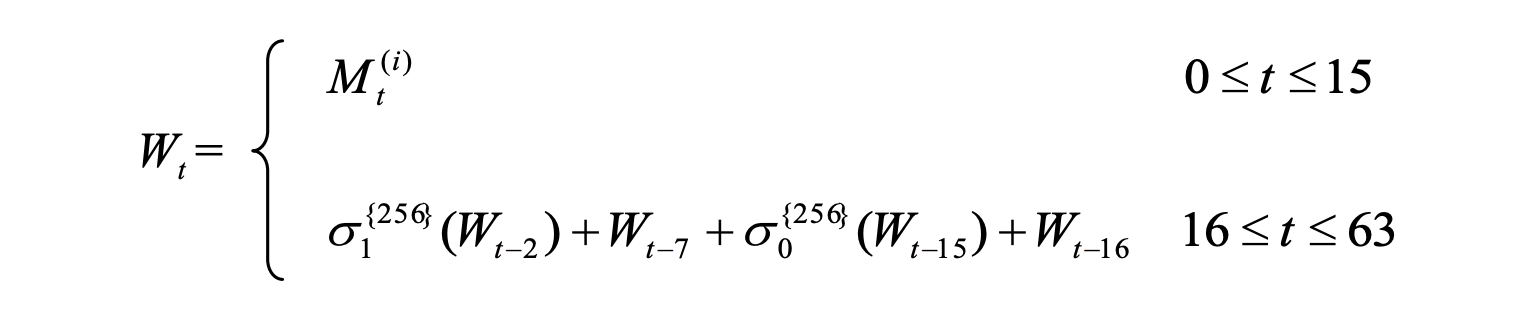
Here’s a example of how you might prepare the message schedule:
func prepareSchedule(bl []byte) []uint32 {
sch := make([]uint32, 64)
for i := 0; i < 16; i++ {
sch[i] = binary.BigEndian.Uint32(bl[i*4 : (i+1)*4])
}
for i := 16; i < 64; i++ {
s0 := rotateRight(sch[i-15], 7) ^ rotateRight(sch[i-15], 18) ^ rightShift(sch[i-15], 3)
s1 := rotateRight(sch[i-2], 17) ^ rotateRight(sch[i-2], 19) ^ rightShift(sch[i-2], 10)
sch[i] = s1 + sch[i-7] + s0 + sch[i-16]
}
return sch
}
Now that the message schedule is prepared we need to process it. This function is a pivotal component of the SHA-256 algorithm, responsible for transforming the working variables based on the message schedule, thus producing the intermediate hash values for each round of computation.
Here’s a example of how you might process the message schedule:
func processSchedule(H [8]uint32, ws []uint32) [8]uint32 {
// initialize the eight working vars
// with the (i-1) hash value
a, b, c, d, e, f, g, h := H[0], H[1], H[2], H[3], H[4], H[5], H[6], H[7]
// rotation processing
for t, w := range ws {
S0 := rotateRight(a, 2) ^ rotateRight(a, 13) ^ rotateRight(a, 22)
S1 := rotateRight(e, 6) ^ rotateRight(e, 11) ^ rotateRight(e, 25)
t1 := h + S1 + ch(e, f, g) + k[t] + w
t2 := S0 + maj(a, b, c)
// rotate working vars
h = g
g = f
f = e
e = d + t1
d = c
c = b
b = a
a = t1 + t2
}
// compute the ith intermidate hash value
H[0] += a
H[1] += b
H[2] += c
H[3] += d
H[4] += e
H[5] += f
H[6] += g
H[7] += h
return H
}
At the beginning of the function, the eight working variables (a to h) are
initialized with the previous hash values (H[0] to H[7]).
Inside the loop that iterates over each element w in the message schedule ws,
the processing begins with the calculation of two values, S0 and S1, which
involve bitwise rotations of the working variables a and e. Now, we can calcuate
the temporary variables t1 and t2. After these calculations, the working variables
are updated in a specific order, defined in the standard as follows:
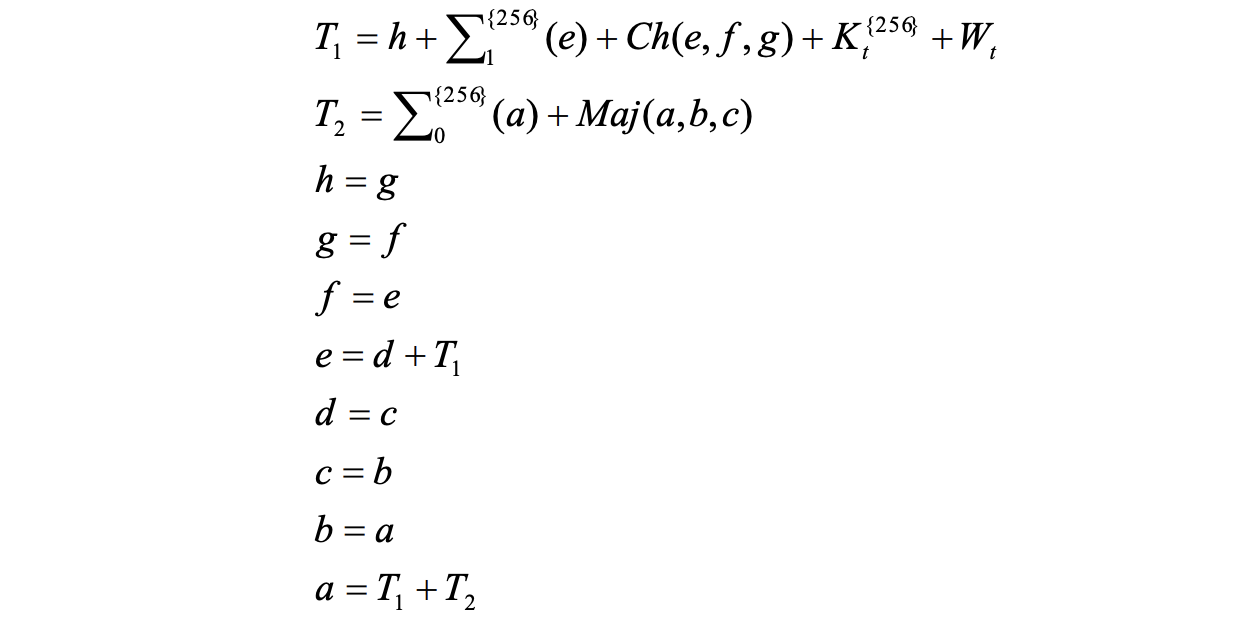
The loop continues to process the entire message schedule, and for each iteration,
the working variables are transformed based on the intermediate calculations. Once
the loop completes, the H array of hash values is updated with the updated
working variables. Each element of H is incremented by the corresponding value
of the working variable (a to h). Finally, the updated H array, now containing
the new intermediate hash values is returned.
If we put all the previous steps together, we get the following:
func Hash(m []byte) []byte {
// preprocessing consists of three steps: padding
// the message, parsing the message into message
// blocks, and setting the initial hash value
mpd := padding(m)
bls := parsing(mpd)
H := [8]uint32{init0, init1, init2, init3, init4, init5, init6, init7}
// compute hash
for _, bl := range bls {
// prepare the message schedule
ws := prepareSchedule(bl)
// process the message schedule
H = processSchedule(H, ws)
}
// convert to byte slice
hash := make([]byte, size)
for i, h := range H {
binary.BigEndian.PutUint32(hash[i*4:i*4+4], h)
}
return hash
}
The Hash function embodies the complete process of generating a SHA-256 hash
for an input message. It orchestrates a series of well-defined steps, beginning
with preprocessing and culminating in the production of the hash value.
After processing all the message blocks (N), the intermediate hash values are
consolidated into a single 256-bit message digest (hash value) of the message,
which can simply be described as:
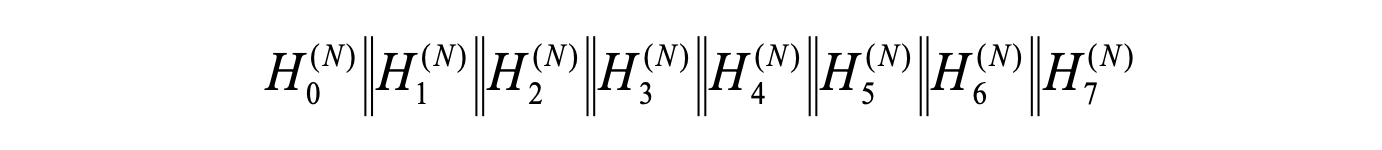
In summation, the Hash function encapsulates the complexity of SHA-256 hashing,
seamlessly traversing through preprocessing, message schedule preparation,
processing, and hash value conversion. This consolidated and structured approach
ensures the generation of a secure and reliable SHA-256 hash for the given input
message, adhering to the algorithm’s rigorous standards of data integrity and
cryptographic security.
In case you are interested, the full implementation of the algorithm can be found on my Github repository as well with some working examples. Happy Coding!
References
- FIPS PUB 180‐4, Secure Hash Standards, Federal Information Processing Standards Publication. Information Technology Laboratory, National Institute of Standards and Technology, Gaithersburg, MD, 2008.