
Some decades ago, with the creation of modern computer systems, came a set of principles that shaped the way modern software is built, and it is known as the Unix philosophy. While still in practice by some programmers, it has been pushed to the sidelines due to the advent of machines with practically infinite memory. Yet this philosophy remains astonishingly relevant today, emphasizing building simple, modular, and extensible code that can be easily maintained and repurposed.
To understand the principles that arose from the experience of these Unix programmers, such as Ken Thompson and Dennis Ritchie, we will start with a simple problem and tackle it from two different perspectives.
Say you have a web server that appends a line to a log file every time it serves a request [1]. For example, using the nginx default access log format, one line of the log might look like this:
212.38.209.48 — — [27/Dec/2022:19:25:21 +0000] “GET /js/foo.js HTTP/1.1” 200 1375 “http://bar.com/" “Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.115 Safari/537.36”
There’s a lot of information in that line. To interpret it, you need to look at the definition of the log format, which is as follows:
$remote_addr — $remote_user [$time_local] “$request” $status $body_bytes_sent “$http_referer” “$http_user_agent”
Thus, this one line of the log indicates that on December 27, 2022, at 19:25:21
UTC, the server received a request for the file /js/foo.js from the
client’s IP address 212.38.209.48. The user was not authenticated,
so $remote_user is set to a hyphen (-). The response status was 200
(i.e., the request was successful), and the response was 1,375 bytes in size.
The web browser was Chrome 40, and it loaded the file because it was referenced
in the page at the URL http://bar.com/.
Now, say you are assigned a very common task, and you want to find your website’s three most popular pages.
The first way to approach this problem would be to write a simple program. Using the Python programming language, it could look like this:
from collections import defaultdict
counts = defaultdict(int)
with open("/var/log/nginx/access.log") as file:
for line in file:
url = line.split()[6]
counts[url] += 1
top3 = sorted(counts.items(), key=lambda item: item[1], reverse=True)[:3]
for top in top3:
print(top[1], top[0])
The counts variable is a hash table that keeps a counter for the number of times
we’ve seen each URL. A counter is zero by default. From each line of the log, we
consider the URL the seventh white space-separated field. Then we increment the
counter for the URL in the current line of the log. Finally, we sort the hash
table contents by counter value (descending) and print out the top three entries.
The second approach that you can take is to execute the following chain of commands in a Unix shell:
$ cat /var/log/nginx/access.log |
awk '{print $7}' |
sort |
uniq -c |
sort -r -n |
head -n 3
The command above reads the entire log file. It splits each line into
fields by white space and outputs only the seventh field from each line,
which is the requested URL. It alphabetically sorts the list of requested
URLs. If some URL has been requested n times, then after sorting, the
file contains the same URL repeated n times in a row. The uniq command
filters out repeated lines in its input by checking whether two adjacent
lines are identical.
The -c option tells it to also output a counter: for every distinct URL,
it reports how many times that URL appeared in the input. The second sort
sorts by the number (-n) at the start of each line, which is the number
of times the URL was requested. It then returns the results in reverse (-r)
order, i.e., with the largest number first. Finally, the head outputs just
the first three lines (-n 3) of input and discards the rest.
Both approaches solve our original problem and give an output that could look like the following:
4149 /foo.html
2363 /css/foo.css
415 /js/foo.js
Before we compare the two solutions, let’s define this mysterious philosophy. In 1978, Douglas McIlroy formally documented the Unix Philosophy in a Bell Labs journal. Those notes were summarized in Peter Salus’s book, A Quarter Century of UNIX, in these three easy points:
- Write programs that do one thing and do it well.
- Write programs to work together.
- Write programs to handle text streams because that is a universal interface.
Over time, many programmers have added to or altered this philosophy slightly, but these remain the core principles.

Coming back to our original problem, it should start to be clearer that the second approach we saw earlier is the one that adhered to the Unix philosophy. But why?
Each command in the chain of commands is itself a program built by someone who dedicated all their time and effort to creating that one specific functionality. Consequently, these small programs are easy to handle, maintain, and debug. In the Python program, we embedded all the functionality into one single program, making it less concise than it could be.
Additionally, all the chains of commands are designed to work well with other programs. It emphasizes the idea of putting programs together like small blocks in which the output of one program is the input of another. Using these simple building blocks, we will build complex software. This leads its way to extensibility again. In the Python program, we can only execute that code for that given nginx log file no matter what. No extensibility is present, which will lead to monolithic software if we are not careful.
Finally, if you expect the output of one program to become the input of
another program, that means those programs must use the same data format,
in other words, a compatible interface. In Unix, that interface is a file
descriptor. A file is just an ordered sequence of bytes. Because that is
such a simple interface, many different things can be represented using the
same interface: an actual file on the filesystem, a communication channel to
another process (Unix socket, stdin, stdout), a device driver (/dev/audio
or /dev/usb), a socket representing a TCP connection, and so on.
This might seem normal to you, but if you truly think about it, it is insane how this uniform interface has provided the base for all data exchange in modern software. It is worth noting that most Unix tools represent the sequence of bytes as ASCII text since that is a universal interface, but other data formats could have been chosen if they were universal in nature. Consequently, the Python program can only work in isolation; it has no uniform interface, and thus, it cannot further interoperate with other programs.
Ultimately, both approaches solve the same problem. There is no way of saying which approach is better. The second approach can indeed scale to bigger datasets that don’t fit in memory by spilling to disk, while the system’s available memory bounds the first approach. But I think the takeaway here is the ideas behind this philosophy. I believe that embracing the ideas of simplicity, extensibility, and interoperability leads to amazing software!
“This is the Unix philosophy: Write programs that do one thing and do it well. Write programs to work together. Write programs to handle text streams, because that is a universal interface.” — Doug McIlroy
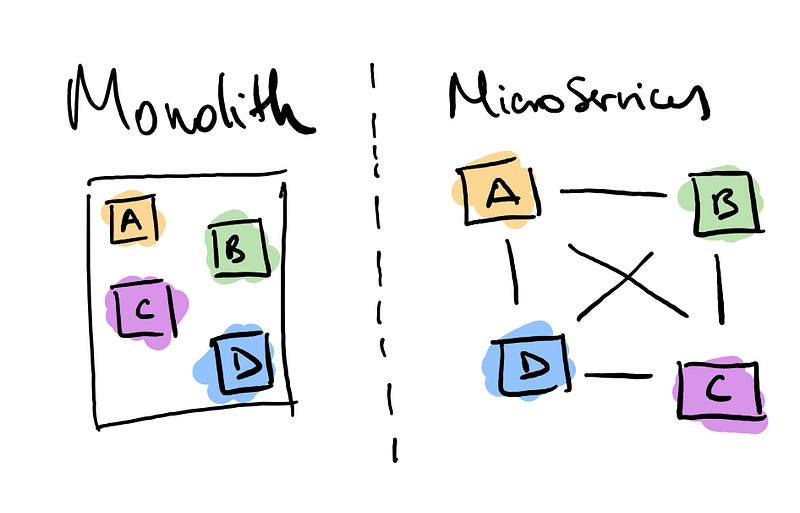
The Unix philosophy, it’s not just about some command line programs and shell pipelines. These set of principles are still astonishingly relevant today. For instance, the traditional way of building enterprise applications, using a monolithic approach, has become problematic as applications get larger and more complex. As a result, the microservices software development architecture was created, in which applications are structured as collections of loosely coupled services that communicate through a uniform interface, usually HTTP. This makes them easier to build and, more importantly, expand and scale. Can you catch the pattern?
References
- Kleppmann, M. (2018) Designing data-intensive applications: The big ideas behind reliable, scalable, and maintainable systems. Sebastopol, CA: O’Reilly Media.
- Singh, S. (2022) What is the unix philosophy - 5 tenants of the philosophy, LinuxForDevices. Available at: https://www.linuxfordevices.com/tutorials/linux/unix-philosophy.
- Atchison, L. (2018) Microservice architectures: What they are and why you should use them, New Relic. Available at: https://newrelic.com/blog/best-practices/microservices-what-they-are-why-to-use-them.